이진탐색
- 오름차순 정렬돼있는 리스트 내에서 특정 값의 인덱스를 찾는 알고리즘
7이라는 숫자의 인덱스를 빠르게 찾는 방법은
리스트의 절반 인덱스 값을 확인하고 그 값보다 작으면,
그 앞의 절반 리스트만을 남기고
또 그 리스트의 절반 인덱스 값을 확인하고 또 그 값보다 작으면
절반의 리스트만을 남기는 절차를 계속 진행한다.



- 장점
- 빠른 속도
- 시간복잡도 O (logN)
단점
- 정렬된 리스트에서만 사용 가능
정렬
- 안정정렬 vs 불안정 정렬
-- 중복된 값의 순서 보장 여부
In-place정렬 vs Out-of-place정렬
- 원본 데이터 내 정렬의 여부
Bubble SORT
- 인접한 두 원소를 비교
- 두 값이 정렬되지 않았다면 SWAP
- 정렬이 완료된 원소를 제외하고 위의 과정을 반복
- O(N^2)
- 안정정렬
- 인플레이스 정렬
앞 값과 뒷 값을 비교해서 앞의 값이 더 크면 SWAP

모든 리스트의 정렬을 한 번 하게 되면 맨 마지막 값이 정렬이 됨
즉, 다음 정렬에서는 맨 마지막을 비교 안해봐도 된다.

삽입 정렬
- 리스트의 앞에서부터
- 이미 정렬된 서브 리스트의 값들과 비교
- 자신의 위치에 삽입
- 안정정렬
- 단순 알고리즘
- 데이터 이동 많음
- 리스트의 데이터가 어느정도 정렬이 돼있는 상태일 경우 데이터의 이동이 적어짐
삽입 정렬의 시간복잡도
- 평균 O (n^2)
- 최선 (모두 정렬이 돼있는 경우 O(n))
- 최악 (역으로 정렬 O(n^2))
Merge Sort

병합정렬은
- 분할 정복 알고리즘
- 재귀를 이용하여 구현
- NlogN
원소들을 분할 할때 log2 N
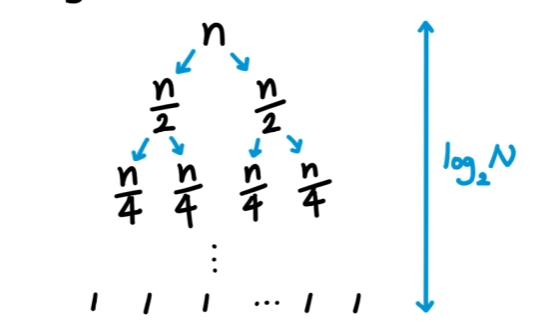
분할 된 원소들을 정렬할 때 N

퀵 정렬
시간 복잡도 O (N log N)
- 참조 지역성
- 한번 결정된 pivot값은 이후 연산에서 제외
- 추가적인 메모리 공간 사용 X
- 불안정 정렬
- Divide and conquer 분할 정복 사용

CPU는 연산에 필요한 값이 CACHE에 있다면 CACHE를 먼저 탐색하고
CACHE에 없다면 그때 RAM에 접근한다. 그리고 나서 다음을 위해 그 데이터를 캐시에 올린다.
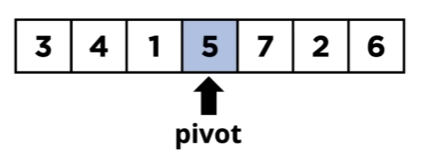
머지소트의 피봇값은 가운데, 맨끝 상관이 없다.
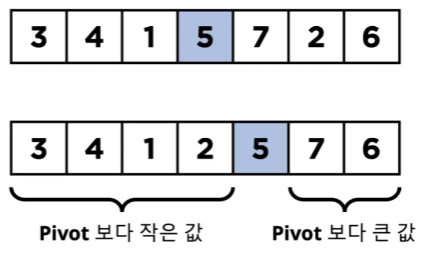
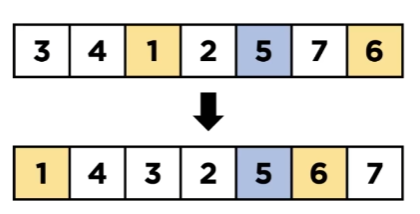
피봇을 정하고 피봇을 기준으로 값을 앞 뒤로 정렬한다.
시간복잡도
- 평균 O (N log N)
- 최악
-> 정렬된 리스트 O (n^2)
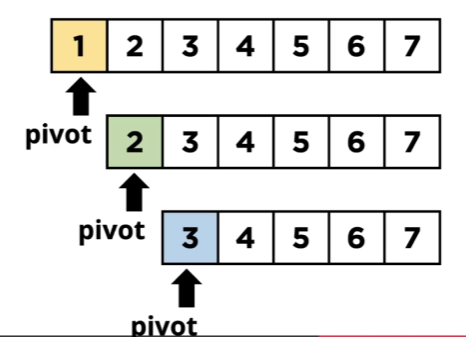
최악의 시나리오는 다음과 같다.
'자료구조&알고리즘' 카테고리의 다른 글
| 힙 Heap 자료구조 (0) | 2022.04.08 |
|---|---|
| 트리 자료구조 (이진트리) (0) | 2022.04.08 |
| HASH와 HASH Collision 그리고 Chaining (해시 자료구조) (0) | 2022.04.07 |
| 스택과 큐에 대하여 (0) | 2022.04.07 |
| Double Linked List (이중 연결 리스트) (0) | 2022.04.07 |