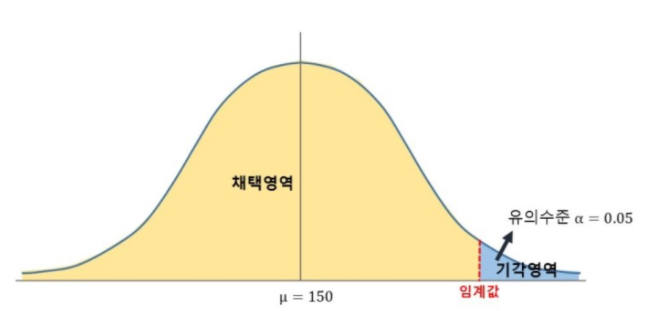
주어진 상황에 대해서, 하고자 하는 주장이 맞는지 아닌지를 판정하는 과정. 모집단의 실제 값에 대한 sample의 통계치를 사용해서 통계적으로 유의한지 아닌지 여부를 판정함 증명된 바가 없는 주장이나 가설을 표본 통계량에 입각하여, 주장이나 가설 진위 여부를 판단, 증명, 검정하는 통계적 추론 방식이다. 귀무 가설 직접 검정 가설이 되는 가설, 표본을 관찰하고 이 자료들이 이럴 거라고 세운 가설이다. 일단 귀무 가설이 옳다고 시작 귀무 가설은 기각이 목표(reject) 대안 가설 귀무 가설의 대안이 되는 가설, 귀무 가설이 기각이 되면 받아 들여지는 가설임 대안 가설은 채택이 목표다 유의 수준 귀무 가설이 실제로 옳은데도, 기각할 오류 귀무 가설을 기각할 때 따르는 위험 귀무 가설이 기각인지 채택인지 판..