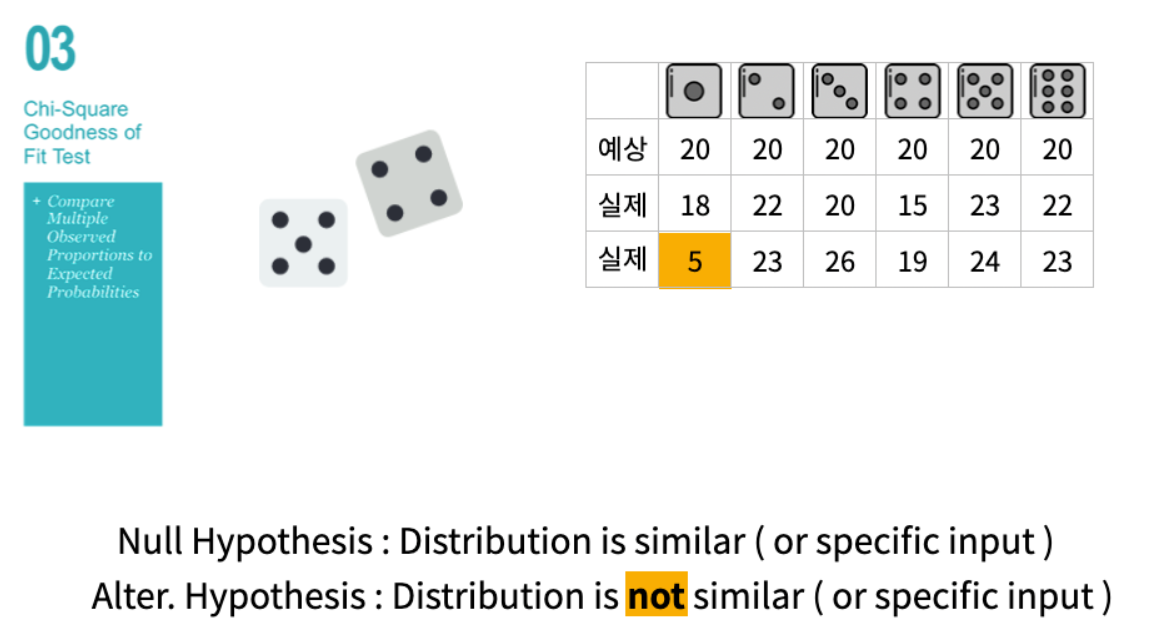
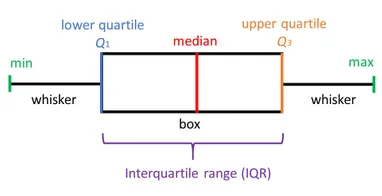
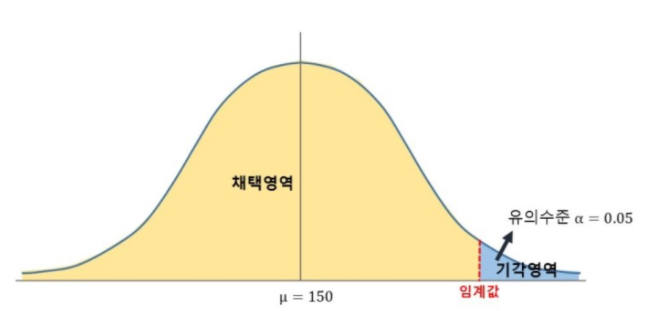
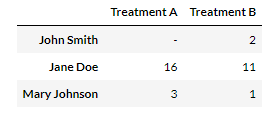
2개 이상 그룹의 평균에 차이가 있는지를 가설 검정하는 방법 통계학에서 두 개 이상 다수의 집단을 서로 비교하고자 할 때 집단 내의 분산, 총평균 그리고 각 집단의 평균의 차이에 의해 생긴 집단 간 분산의 비교를 통해 만들어진 F분포를 이용하여 가설검정을 하는 방법 F 분포? F분포는 분산의 비교를 통해 얻어진 분포비율이다. 이 비율을 이용하여 각 집단의 모집단분산이 차이가 있는지에 대한 검정과 모집단평균이 차이가 있는지 검정하는 방법으로 사용한다. 즉 F = (군간변동)/(군내변동)이다. 만약 군내변동이 크다면 집단간 평균차이를 확인하는 것이 어렵다. 분산분석에서는 집단간의 분산의 동질성을 가정하고 하기 때문에 만약 분산의 차이가 크다면 그 차이를 유발한 변인을 찾아 제거해야 한다. 그렇지 못하면 분산..