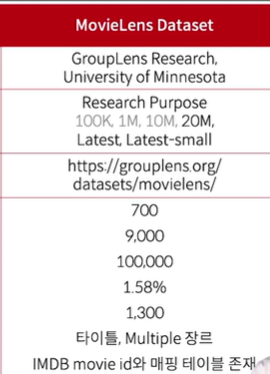
- 작은 데이터, 큰 데이터로 나눠져 있음
데이터 Record
영화 평점 예측


- 개인화 추천
- Explicit 명확한 데이터
- CBF, CF
- 평점 예측 모델

Pandas 라이브러리를 활용한 데이터 분석
- datetime
- apply
- groupby
- merge
- sample
- drop
- agg
- display
# 초로 나와있는 col을 년월일초로 변경 하여 date라는 df로 만들어줌
df['date'] = pd.to_datetime(df['timestamp'].astype(int), unit='s')
# year라는 col를 생성한다 date에서 year만 가져온다.
df['year'] = df['date'].apply(lambda x: x.year)
# year로 묶어서 count해준다.
yearCounts = df.groupby('year').size()
#barplot으로 시각화
yearCounts.plot(kind='bar', figsize=(12,8), label='counts', legned=True)
#학습 데이터 랜덤 추출
train = df.sample(frac=0.9, random_state=1)
train['type'] = 'train'
#테스트 데이터 만들기
test = df.drop(train.index)
test['type'] = 'test'
#mae 구하기
mae = avgPredErrors.abs().mean()
#rmse
rmse = math.sqrt(avgPredErrors.pow(2).mean())
#유저 별로 rating의 평균 값을 구하기, agg 함수를 통해서 각각의 user에 대해서 평균을 구한다.
userAvgRatings = train[['userId', 'rating']].groupby('userId').agg('mean')
#merge를 이용하여 df 두개를 합치기
pd.merge(userAvgPred, userAvgRatings, how='left', left_on=['userId'], right_on=['user_id'], right_index = False)
#이미지 url을 display하는 라이브러리
# 5개의 이미지 출력 됨
from IPython.display import Image, display
for i in range(0, 5):
print(dfMovie['imgurl'].iloc[i])
'추천시스템(RS)' 카테고리의 다른 글
| 추천 시스템이란? (0) | 2022.07.12 |
|---|---|
| CBF 기반 예측 (0) | 2022.07.11 |
| 추천시스템 고려사항 (0) | 2022.07.11 |
| 추천시스템 성능 평가 (0) | 2022.07.11 |
| 추천시스템 분류 (0) | 2022.07.11 |