데이터 조작 및 분석을 위한 Python 프로그래밍 언어 용으로 작성된 소프트웨어 라이브러리 입니다 . 특히 숫자 테이블과 시계열 을 조작하기 위한 데이터 구조 와 연산을 제공합니다
DataFrame
테이블 형식의 데이터 (tabular, rectangular grid 등으로 불림)를 다룰 때 사용한다.
Data Set
하나 이상의 데이터베이스 테이블에 해당하며 , 테이블의 모든 열 은 특정 변수를 나타내고 각 행은 해당 데이터 세트의 주어진 레코드에 해당한다.
Data Set을 DataFrame 형식으로 나타내면 아래 그림과 같다.
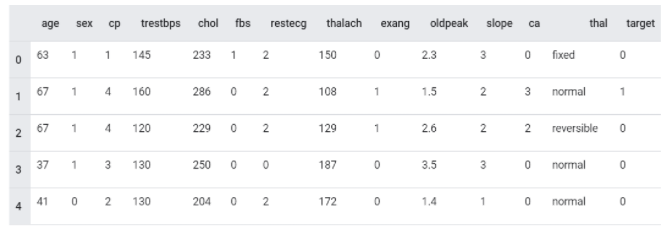
column: age, sex, cp 등 열이 어떻게 구성되어야 할 지에 대한 구조를 제공한다. (Data Set의 Feature라고도 한다.)
row: 레코드(record) 또는 튜플(tuple)로 불리기도 하며, 어떤 테이블에서 단일 구조 데이터 항목을 가리킨다. (index라고도 한다.)
결측치: Na, Null, NaN, 0, Undefined
undefined: 선언은 되었으나 값이 할당 되지 않은 상태
null: 아무런 값도 나타내지 않는 특수한 값 (초기화 해주어야 null 상태가 존재 할 수 있음)
NaN: JS에서만 존재하는 '숫자가 아니다'를 의미하는 값
Na와 NaN는 하나의 값 으로 인식하는 반면 NULL은 값 자체가 없음
0: 값에 숫자 0이 들어있는 경우
Na: not available
NaN: Not a Number
String Replace
일반적으로 머신러닝 모델링에서는 문자열로 이루어진 값은 사용하지 않습니다. (매우 복잡한 문제입니다.)
- 문자를 숫자로 바꾸기 위해 숫자가 아닌 부분을 제거
- 문자를 숫자로 형변환 (type casting)
형 변환(Type casting)
변수의 type을 강제로 다른 type으로 변경하는 것
형 변환이 왜 필요할까?
우리가 자주 사용할 머신러닝 라이브러리인 사이킷런은 문자열 값을 입력 값으로 처리하지 않기 때문에 숫자형으로 변환해야 한다. 따라서 이 때 변환 할 때 형 변환이 중요하다.

int() - 정수형으로 바꿈
float() - 실수형으로 바꿈
str() - 문자열로 바꿈
hex() - 16진수로 바꿈
oct() - 8진수로 바꿈
bin() - 2진수로 바꿈
tuple() - 튜플로 변환
list() - 리스트로 변환
set() - Set형으로 변환
- pandas 객체에 열 혹은 행에 대해 함수를 적용하게 해주는 메서드
- 데이터의 모든 문자열에 대해서 일일히 함수를 반복 할 수는 없어서 사용하는 함수
Apply( ) 예시
def tofloat(str):
ans = float(str.replace(',',''))
return ans
for col in headers:
try:
if col != '분기' and (df[col].dtypes == object) :
df[col] = df[col].apply(tofloat)
except:
pass사용자 정의 함수 tofloat( )을
df의 '분기'를 제외한 모든 columns에 적용하는 예제이다.
예를 들어 한 records에 13,258 라는 값이 들어있었다면,
str 자료형을 float으로 바꾸면서, 13258.0 이라는 값으로 저장되게 한다.
따라서 Apply( )는
사용자 정의 함수, 내장 메소드 등 어떠한 함수를 행과 열에 반복문 없이 적용 시킬 수 있는 장점이 있다.
'ALL NIGHT STUDY' 카테고리의 다른 글
| Tidy 데이터 (0) | 2021.09.16 |
|---|---|
| Concat/Merge (0) | 2021.09.16 |
| Feature Engineering (0) | 2021.09.16 |
| 데이터 전처리(Pre-Processing) (0) | 2021.09.16 |
| EDA(Exploratory Data Analysis) (0) | 2021.09.16 |