데이터 파이프라인 구성방안
1. 회사 내 데이터적 요구사항 빠른 대응
2. 지속적이고 에러가 없어야 한다.
3. 시스템적으로 발생하는 문제에 대해서 유연한 scability
4. 스케일 업, 아웃이 자유로워야 한다.
5. 이벤트성 데이터 부하에도 처리가 가능해야 한다.
6. 데이터가 쌓이는 공간에 문제가 없어야 한다.
7. 수집 데이터의 유연성
8. 쉬운 분석 데이터 포멧
- json으로 저장하는 것이 좋음
데이터 기반 오픈소스, 클라우드 서비스가 정말 많이 나왔음

Data Lambda 아키텍쳐

먼저 Raw data store에 저장한다.
batch 나 real-time 프로세스로 servig data store에 저장한다.
Data Warehouse에 저장할 수 있음 -> 마트를 구성할 수 있음, Feature Store 등
마지막은 데이터 분석, 시각화로 종착이 된다.

핀포인트 서비스 : 특정 앱이나 서비스에서 나오는 데이터를 저장, SDK 가지고 배포하면 저장하는 비용이 적음
아마존 핀포인트로 데이터 수집하고 키네시스를 통해서 S3 data Lake에 저장할 수 있음

AWS EMR 서비스에서 Spark를 배포한다. DMS 는 DB에서 가져올때 서비스 부하를 줄여줄 수 있는 장점이 있다.
비용, 시간을 고려를 해야 한다.
키네시스 분석을 통해서 실시간 데이터 분석을 가능하게 할 수 있다.
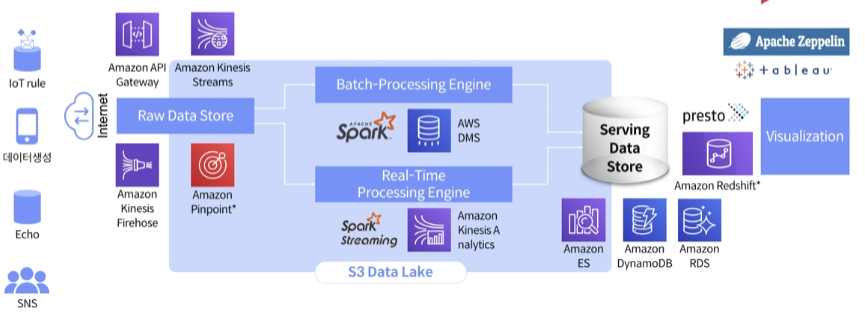
아마존 ES는 데이터를 계속 쌓으면 유지 비용이 너무 많이 듬
Nosql 아마존 다이나모DB
아마존 RDS 는 mysql
아마존 Redshift는 데이터 분석툴
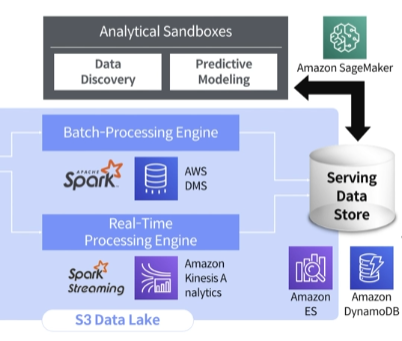
아마존 세이지 메이커를 통해서 ML 예측을 할 수 있음
Data Cataloging (AWS GLue)
데이터 메타 데이터를 잘 만들어야 분석하기 용이함
Data Security and Governance
꼭 데이터 보안과 거버넌스를 잘 고려해서 만들어야 함.
WEB에서 발생하는 Event



특정 버튼을 누르는 EVENT
일련의 이러한 사이클을 분석 -> 우리 제품을 보고 주문을 하는, 메뉴 선택하는데 도움이 되게 분석
APP에서 발생하는 Event
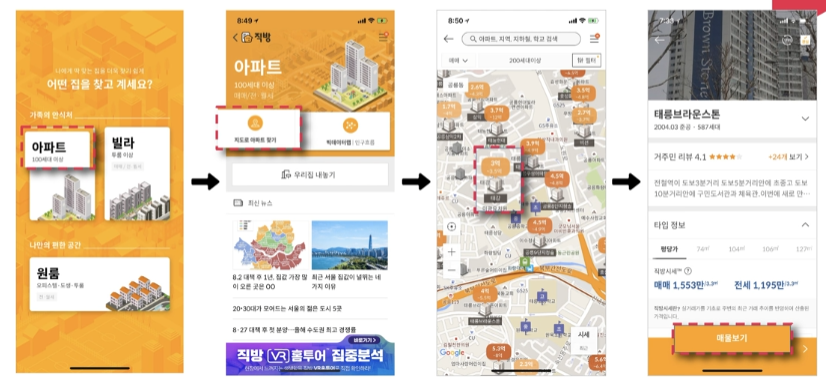
아파트 클릭 -> 지도 -> 지도클릭 -> 매물보기
일련의 사용자의 네비게이션 데이터를 수집할 수 있음
어떻게 파이프 라인을 구성해야 효율적인지 고민해봐야함
WEB에서 발생하는 Event

appsflyer, adbrix
마케팅 관련 tool
니즈에 맞는 데이터 수집 파이프라인을 잘 구성할 줄 알아야 함.
'AWS DB PIPELINE' 카테고리의 다른 글
| Data PIPELINE 용어 정리 (0) | 2022.07.02 |
|---|---|
| Kafka install in EC2 (0) | 2022.06.30 |
| EC2, S3, RDS, api-gateway, CloudWatch (0) | 2022.06.22 |
| 데이터 파이프라인 아키텍쳐 기본 설명 (0) | 2022.06.20 |